One of the scary things about social networks like Facebook et al, is just how much information we’re happy to upload for the world to see. So much for long term privacy, eh? Especially with tools like Pipl around, which scan through these networks to gather whatever information they can.
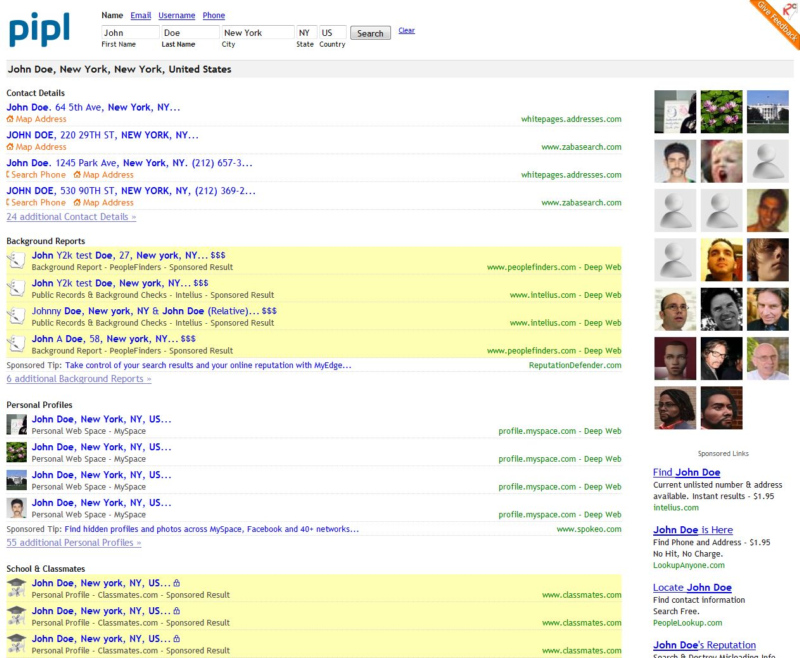
Do a search for someone on Pipl and you’ll receive a shed load of information culled from just about every deep web source and social network in the universe. White Pages, MySpace, Flickr, LinkedIn, Twitter, PDF docs, Classmates.com…you get the picture. Oh and you will. Get their picture, if it’s available somewhere. It’s fast, and very comprehensive. Did we mention scary already? Of course the one thing it won’t do is give you any info on Luddites. But you knew that already, didn’t you?
![]()
One tiny bit of interesting trivia is the fact that Google throws up 2.1 billion results for Pipl, which must be a record for a small startup?
Pipl’s query-engine helps you find deep web pages that cannot be found on regular search engines. Unlike a typical search-engine, Pipl is designed to retrieve information from the deep web, our robots are set to interact with searchable databases and extract facts, contact details and other relevant information from personal profiles, member directories, scientific publications, court records and numerous other deep-web sources.



Very scary.
Very! :-)
I am a private detective and I use pipl everyday in my investigations. One of the best people search sites